Seiten, über die ich einmal stolperte, an denen ich mich erfreut habe, die dann aber wieder in Vergessenheit geraten sind. Durch die Korrektursichtung blättere ich in der Sammlung meiner Entdeckungen von früher. Viele der Links sind inzwischen mit einem offline markiert. Die automatische Prüfung auf tote Links arbeitet leise im Hintergrund. Sie erwischt nur Seiten, die komplett unerreichbar sind, umgewidmete Seiten werden nicht erkannt.
Wo ich die Beiträge sichte, blicke ich das ein oder andere Mal in die Vergangenheit des Netzes. Aus Nostalgie werfe ich einen Blick in die Wayback Machine wenn eine spannend klingende Seite von damals als offline angezeigt wird. Übrigens: wer die Suchmaschine DuckDuckGo verwendet, kommt sehr bequem ins Archiv einer Seite. !wayback in den Suchschlitz zum nicht mehr funktionierenden Link packen und es wird die Wayback Machine geöffnet mit der Übersicht der vorhandenen Sicherungen (Snapshots) des angegebenen Links. In einer Jahresleiste wird mittels eines Balkendiagrams angedeutet, wie viele Sicherungen existiern. Wählt man ein Jahr aus sind Tage mit vorhandenen Sicherungen bläulich markiert (siehe Abb. 1). Klickt man darauf, erhält man eine Liste der Snapshots. Klickt man auf einen Sicherungszeitpunkt, gelangt man auf die gespeicherte Seite.
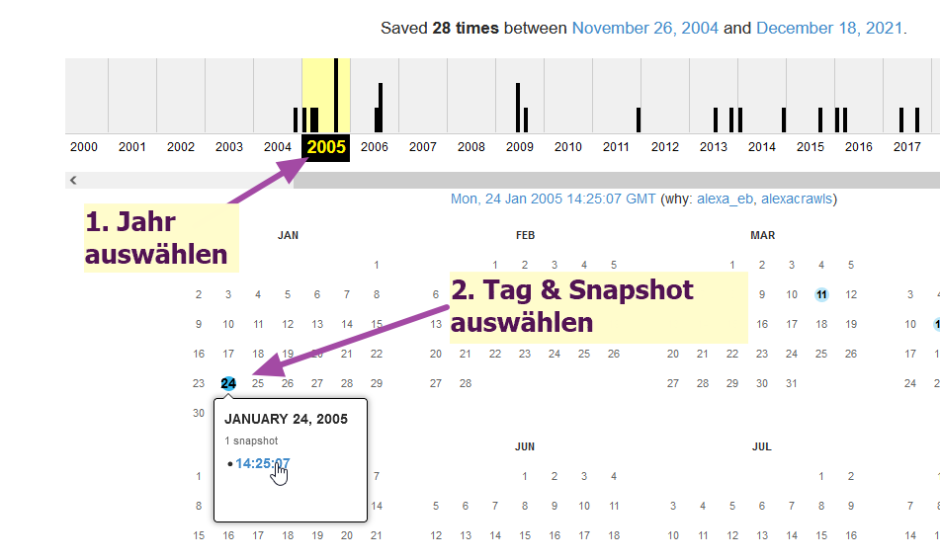
Und wo ich so den Namen der so nützlichen Funktionaliät((im Dauergebrauch bei mir auch !wiki)) nachschlage (Bangs), stelle ich fest, dass es sogar noch schneller geht: !wbm. Möchte man das Internet Archive motivieren, eine Sicherung einer Seite zu speichern, z.B. weil diese historisch relevant werden könnte, kann auch dies via DuckDuckGo über den Bang !save initiiert werden. Ansonsten: Wer ein wenig hinter die Kulissen blicken möchte: im Juli führte Netzpolitik ein Interview mit einem Mitglied des Archive Teams (2023). Lesenswert ist auch der Heise Online Artikel von Pit Noack (2018).
Die Wayback Machine ist natürlich nicht das einzige Projekt, das versucht dem Verschwinden von Informationen im Netz entgegen zu treten. Andere Dienste sind z.B. archive.today (!ais). Salman Ravoof hat im November letzten Jahres einen recht umfangreichen Artikel zum Thema geschrieben (2022), in dem mehr Dienste und andere Möglichkeiten entdeckt werden können. Auch in Awesome OSINT Listen kann zu dem Thema einiges gefunden werden. Neben der rechtlichen Diskussion mag ich hier auch das Fass der Herausforderung der Langzeitarchivierung gerade nicht aufmachen. Diese Sicherungen sind häufig genug alles andere als vollständig. Bilder, Videos, Flash, andere multimediale oder dynamische Inhalte fehlen oder funktionieren einfach nicht mehr, Technologien sterben. Oder die Seiten liegen hinter eine Login- oder Paywall und sind damit für solche Dienste unerreichbar.
Weil ich gerade Flash erwähnt habe: Düster erinnere ich mich an den Bericht über ein Flash-Archiv, über das ich kürzlich etwas gelesen habe. *geht mal nachschauen* Oder vielleicht auch doch nicht so kürzlich: im November 2020 berichtete das Internet Archive über die damals neue Flash-Emulierung in der digitalen Bibliothek. Hier geht's zum Flash Showcase, in dem sich auch das ein oder andere in meinem Blog besprochene Spielchen noch mal ansehen und spielen lässt.
Und weil es so gut passt, drüben bei Netbib wurde vor ein paar Tagen auf die Internet Artifacts verwiesen (via Vorspeisenplatte): ein kleines digitales Museum, in dem man einen Blick auf die Geschichte des Internets werfen kann. Sehr liebevoll gestaltet.
Nachgereicht: Erinnerung und Vergessen


 Mel aka
Mel aka